前言
90%的数据在过去几年里产生,现在和未来将产生大量的数据!
大数据的定义:是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。
数据产生源分类:
- 黑匣子数据
- 社会化媒体数据
- 证劵交易所数据
- 交通运输数据
- 搜索引擎数据
数据种类:
- 结构化数据:关系数据
- 半结构化数据:XML数据
- 非结构化数据:Word, PDF, 文本,媒体日志
操作大数据
这些包括像MongoDB系统,提供业务实时的能力,这里主要是数据捕获和存储互动工作。
NoSQL大数据系统的设计充分利用已经出现在过去的十年,而让大量的计算,以廉价,高效地运行新的云计算架构的优势。这使得运营大数据工作负载更容易管理,更便宜,更快的实现。
一些NoSQL系统可以提供深入了解基于使用最少的编码无需数据科学家和额外的基础架构的实时数据模式。
分析大数据
- 大规模并行处理(MPP)数据库系统和MapReduce提供用于回顾性和复杂性的分析。
大数据的挑战
- 采集数据
- 策展
- 存储
- 搜索
- 分享
- 传输
- 分析
- 展示
Hadoop大数据解决方案
传统的企业方法
谷歌的解决方法
- 使用MapReduce算法,将任务分成小份,并将它们分配到多台计算机,并且从这些机器收集结果并综合,形成数据集。

- 使用MapReduce算法,将任务分成小份,并将它们分配到多台计算机,并且从这些机器收集结果并综合,形成数据集。
Hadoop
- Hadoop使用MapReduce算法运行,用于开发可以执行完整的统计分析大数据的应用程序。

- Hadoop使用MapReduce算法运行,用于开发可以执行完整的统计分析大数据的应用程序。
Hadoop是什么
Hadoop是使用Java编写,允许分布在集群;使用简单的编程模型的计算大醒数据集处理的Apache的开源框架。
- 分布式存储和计算的环境;
Hadoop的架构
在其核心,Hadoop主要有两个层次和两个模块,即:
加工/计算层(MapReduce)
- MapReduce是一种并行编程模型,用于编写普通硬件的设计。MapReduce程序可在Apache的开源框架Hadoop上运行。
存储层(Hadoop分布式文件系统)
- Hadoop分布式文件系统(HDFS)是基于谷歌文件系统(GFS),并提供了一个设计在普通硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。来自其他分布式文件系统的差别是显著。它高度容错并设计成部署在低成本的硬件。提供了高吞吐量的应用数据访问,并且适用于具有大数据集的应用程序。
Hadoop通用:是Java库和其他Hadoop组件所需要的实用工具
HadoopYARN:是作业调度和集群资源管理的框架
Hadoop如何工作?
Hadoop运行整个计算机集群代码。这个过程包括以下核心任务由Hadoop执行:
- 数据最初分为目录和文件。文件分为128M和64M,(128M最好)统一大小块。
- 然后这些文件被分布在不同的群集节点,以便进一步处理。
- HDFS,本地文件系统的顶端﹑监管处理。
- 块复制处理硬件故障。
- 检查代码已成功执行。
- 执行发生映射之间,减少阶段的排序。
- 发送排序的数据到某一计算机。
- 为每个作业编写的调试日志。
Hadoop优势
- Hadoop框架允许用户快速地编写和测试的分布式系统。
- 不依赖硬件,以提高容错和高可用性(FTHA),而Hadoop库本身已被设计在应用册可以检测和处理故障。
- 服务器可以添加或从集群动态删除,Hadoop可继续不中断地运行。
- 开源,基于Java并兼容所有的平台。
Hadoop环境安装设置
Hadoop由GNU/Linux平台支持。
安装前设置
进入Linux环境下,连接Linux使用ssh(安全Shell)。安装以下步骤设立Linux环境。
- 创建一个用户
- 使用“su”命令开启root.
- 创建用户从root账户使用命令“useradd username”.
- now, 可以使用命令打开一个现有的用户账号“su username”.
# 打开Linux终端,输入以下命令创建一个用户
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd
SSH设置和密钥生成
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
$ ssh-keygen -t rss
$ cat ~/.ssh/id_rss.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
安装Java
省去
具体安装参考
下载Hadoop
使用以下命令来提取Hadoop
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit
注意:要下载最新的版本或稳定的版本!
Hadoop操作模式
下载之后,Hadoop的三大模式:
本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。
完全分布模式:完全分布式的最小两台或多台计算机的集群。
Hadoop MapReduce
算法:
通常MapReduce范例是基于向发送计算机数据的位置
MapReduce计划分为三个阶段执行,即映射阶段,shuffle阶段,并减少阶段。
映射阶段:映射或映射器的工作是处理输入数据。一般输入数据是在文件或目录的形式,并且被存储在Hadoop的文件系统(HDFS)。输入文件被传递到由线映射器功能线路。映射器处理该数据,并创建数据的若干小块。
减少阶段:这个阶段是:Shuffle阶段和Reduce阶段的组合。减速器的工作是处理该来自映射器中的数据。处理之后,它产生一组新的输出,这将被存储在HDFS。

实例场景
下面给出的是关于一个组织的电消耗量的数据。包含每个月的用电量,各年的平均。 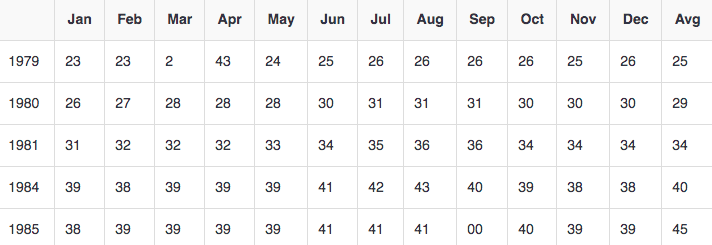
来编写应用程序程序来处理这样的大量数据
- 需要大量的时间来执行
- 将会有一个很大的网络流量,当我们将数据从源到网络服务器等
为了解决这些问题,使用MapReduce框架。
输入数据
上述数据被保存为sample.txt并作为输入。输入文件看起来如下
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45
实例程序
下面给出的是使用MapReduce框架的样本数据的程序
package hadoop;
import java.util.*;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens())
{
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
编译和执行进程单位程序
云里雾里,暂时停止...
源教程(易佰教程),学习笔记!